
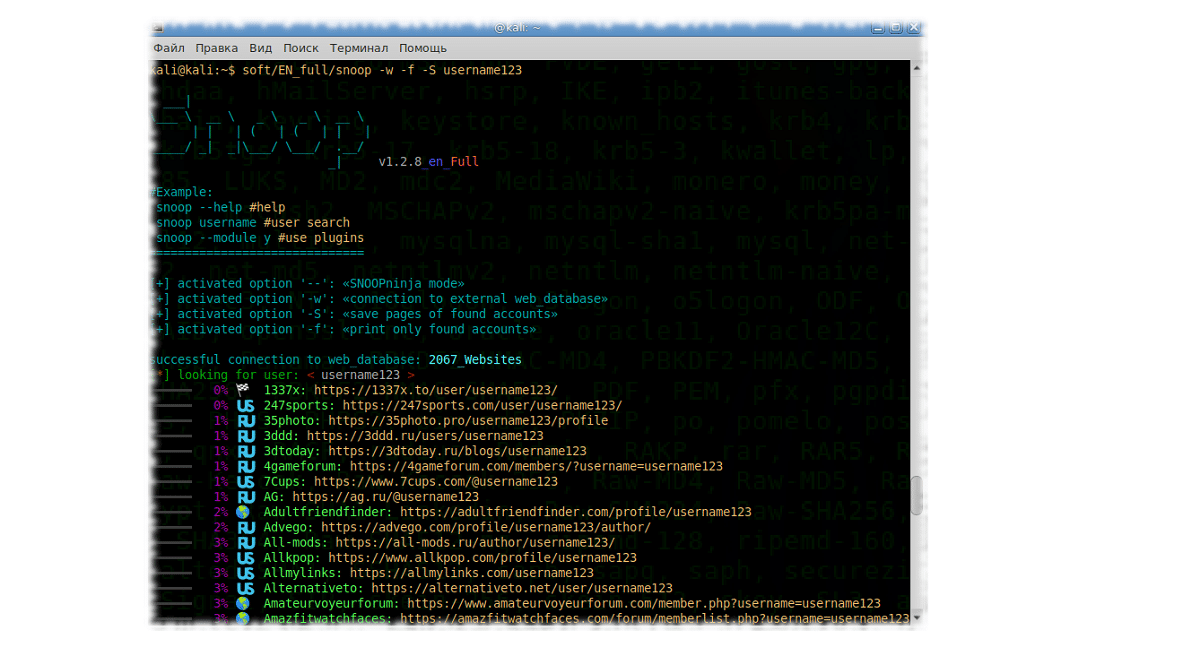
Se dio a conocer el lanzamiento de la nueva versión del «Project Snoop 1.3.3», que se desarrolla como una herramienta forense OSINT que busca cuentas de usuario en datos públicos (bajo el uso de inteligencia de código abierto).
El programa analiza varios sitios, foros y redes sociales para detectar la presencia del nombre de usuario deseado, es decir, permite determinar en qué sitios hay un usuario con el apodo especificado. El proyecto se desarrolló sobre la base de un trabajo de investigación en el campo del scraping de datos públicos.
El código está escrito en Python y tiene una licencia de uso personal restrictiva. Al mismo tiempo, el proyecto es una bifurcación del código base del proyecto Sherlock, suministrado bajo la licencia del MIT (la bifurcación se creó debido a la imposibilidad de expandir la base de sitios).
Project Snoop 1.3.3
En esta nueva versión de la herramienta se agregaron al archivo de videos consejos sobre cómo comenzar a utilizar la herramienta rápidamente para los usuarios novatos que no han trabajado con la CLI.
Para Snoop para Termux (Android), se agregó la apertura automática de los resultados de búsqueda en un navegador externo sin resultados superpuestos en la CLI (a solicitud del usuario, se pueden ignorar los resultados de apertura en un navegador web externo).
Ademas de ello la apariencia fue actualizada de la salida de resultados en CLI al buscar apodos, junto con la salida de licencia de estilo Windows XP que fue actualizada. Se ha actualizado el progreso (anteriormente, el progreso se actualizaba a medida que entraban los datos y por eso parecía que estaba congelado en versiones completas), el progreso se actualiza varias veces por segundo o cuando los datos llegan en el modo de verbalización de la opción ‘-v’.
Tambien se agregó un informe de texto: el archivo ‘bad_nicknames.txt’, que registra la fecha/apodo (s) que faltan, actualizando el archivo (modo de reescritura) durante la búsqueda, por ejemplo, con la opción ‘-u’.
Se agregó una nueva opción ‘–headers’ ‘-H’: configurar manualmente el agente de usuario. De forma predeterminada, se crea un agente de usuario aleatorio pero real para cada sitio o se selecciona/redefine de la base de datos de Snoop con un encabezado extendido para omitir algunas ‘protecciones CF’.
Se agregó el modo de detención de software correcto con la liberación de recursos para diferentes versiones/plataformas de Snoop Project (ctrl + c).
Tambien se destaca que se agregó una pantalla de presentación de snoop y algunos emoji cuando no se especifican los apodos para la búsqueda o se seleccionan parámetros en conflicto en los argumentos de la CLI (excepción: snoop para el sistema operativo Windows – antiguo CLI OS Windows 7).
Se agregaron varios paneles de información: en la lista de visualización de la base de datos, todos; en modo detallado; nuevo bloque ‘snoop-info’ con la opción ‘-V’; con la opción -u, división en grupos apodo (s): válido / inválido / duplicado; en CLI Yandex_parser-a (versión completa).
Tambien se corrigió en los informes csv el tiempo de respuesta del sitio está separado por un ‘signo fraccionario correcto’, teniendo en cuenta la configuración regional del usuario es decir, el número en la tabla es siempre un dígito independientemente del signo fraccionario, que afecta directamente la clasificación de resultados por parámetro.
Los datos por debajo de 1 KB se redondean con mayor precisión, más de 1 KB sin parte fraccionaria Tiempo total (estaba en ms, ahora en s / celda) Al guardar informes con la opción ‘-S’ o en modo normal para sitios que utilizan un método (s) de detección de apodos específicos: (username.salt) Ahora también se calcula el tamaño de los datos de la sesión.
Si quieres conocer más al respecto, puedes consultar los detalles en el siguiente enlace.
Obtener Snoop
Finalmente para quienes estén interesados en poder obtener la herramienta, pueden hacerlo abriendo una terminal y tecleando:
git clone https://github.com/snooppr/snoop
cd ~/snoop
Y podremos instalar las dependencias con:
pip install --upgrade pip
python3 -m pip install -r requirements.txt
Y para conocer más al respecto sobre el funcionamiento de Snoop basta con teclear:
snoop -h
Fuente obtenida de: https://blog.desdelinux.net/project-snoop-una-excelente-herramienta-para-buscar-cuentas-de-usuario-en-datos-publicos/
